

Case Intro: The Business Challenge :
Bright Data is not the kind of product most people buy casually. The official pricing and documentation position it for businesses that need web data, proxies, scraping APIs, datasets, or managed collection workflows at serious scale.
That means the real-world use question is not “can Bright Data scrape a page?” It is “when does a business actually need this kind of infrastructure badly enough to justify it?”
A representative use case in 2026 is a retail or market-intelligence team trying to monitor pricing, assortment, reviews, and category movement across multiple public websites without building a huge data-collection stack from scratch.
That is the problem this case-study angle is built around.
If you want to explore the platform while you read, start with Bright Data here.
What The Official Product Positioning Tells Us :
Bright Data’s official pricing page makes the product range clear. The company is not selling one thing. It is selling a family of web-data products:
- Proxy networks.
- Web Scraper API.
- Scraping Functions.
- Scraping Browser.
- SERP API.
- Web Unlocker.
- Datasets.
- Bright Insights.
That matters because Bright Data can support very different workflows depending on how mature the team is.
A smaller team may use a ready-made API or dataset.
A more advanced team may use proxies, browser automation, or managed services.
An enterprise team may blend several of those together.
That flexibility is part of the point. Bright Data is not forcing every team into the same maturity model.
The Problem Before Bright Data :
Before using a platform like Bright Data, a data-driven business usually runs into a mix of familiar issues:
- Manual collection does not scale.
- Websites block requests.
- Internal scraping stacks become brittle.
- Legal, compliance, and reliability questions start piling up.
- Analysts spend too much time collecting data and not enough time using it.
That is where Bright Data becomes relevant.
The public pricing page and docs frame the product around scale, access, and purpose-built data collection. That means the company is solving not just extraction, but also unlocking, proxy routing, managed infrastructure, and delivery methods.
Implementation And Workflow :
A practical Bright Data rollout usually starts with one question:
- Do we need raw access infrastructure?
- Or do we need a packaged data product?
That decision matters because Bright Data gives buyers more than one route in:
Route 1: Proxy And Scraping Infrastructure
This is the route for teams with engineering capability that want control over:
- Collection logic.
- Browser behavior.
- Request routing.
- Unlocking and CAPTCHA handling.
Route 2: APIs And Data Products
This is the route for teams that care less about scraper engineering and more about getting useful data delivered quickly.
Route 3: Managed Services
Bright Data’s pricing pages also include managed services. The official managed services page currently frames this as:
- Standard project starting from $1,000 per month.
- One-time setup from $500 per standard scraper.
- Usage from $4 per 1,000 requests.
That is a very different buying motion than a lightweight self-serve SaaS tool. It is closer to infrastructure plus service.
Results And What Changes Operationally :
The clearest result of a platform like Bright Data is not a flashy dashboard screenshot. It is operational leverage.
When the data pipeline works, teams can:
- Monitor pricing faster.
- Track changes across sources more consistently.
- Reduce the internal time spent fighting blockers.
- Shift analyst time toward interpretation and action.
- Expand data programs without rebuilding collection infrastructure from zero.
That is the real business case.
The product’s value grows when the company already knows what it wants to observe and how it will use the output.
That is also why the strongest Bright Data use cases are usually tied to an operating metric:
- Price monitoring.
- Competitive assortment tracking.
- Lead enrichment.
- Marketplace intelligence.
- Search-result visibility.
Key Features That Make The Difference :
Broad Product Coverage –
Bright Data’s pricing page shows the company is not trying to solve only one narrow collection problem. That breadth matters because companies often outgrow their first collection method.
Multiple Pricing Models –
The documentation around billing shows that pricing depends heavily on which Bright Data product is used and how usage is structured. That is actually helpful, because it means the company is not pretending every data workflow fits one flat plan.
Pay-As-You-Go And Usage Logic –
Bright Data’s billing documentation explains concepts like:
- Monthly commitment.
- Pay-as-you-go funds.
- Usage overages.
- Product-specific billing units.
That is important because buyers need to understand what they are actually paying for before scale kicks in.
Managed Service Option –
Not every business wants to manage a web-data program internally. The managed service route is a real differentiator for buyers who care more about output than scraper engineering.
That can be a huge advantage for lean teams. Instead of staffing a bigger data-collection function, they can buy a more complete service layer.
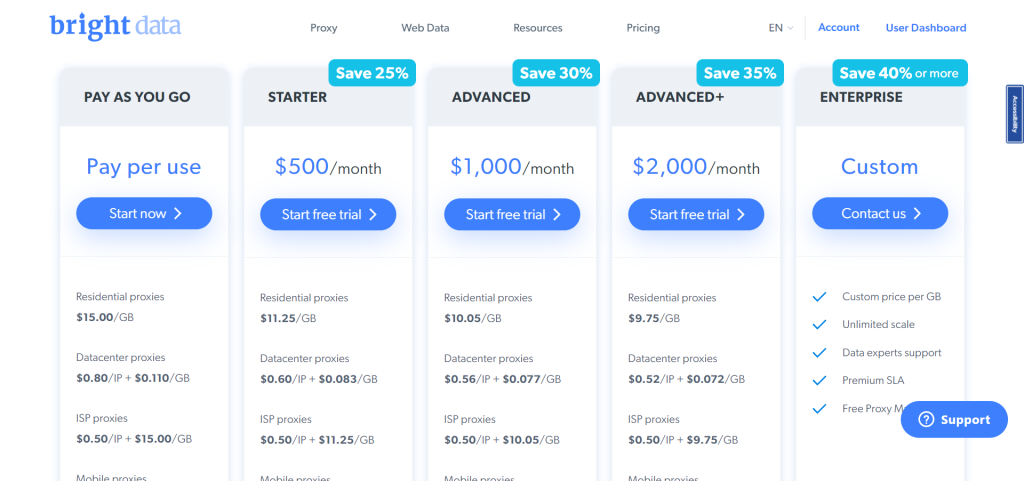
Pricing And Commercial Reality :
Bright Data’s official pricing story is product-specific rather than one simple SaaS table.
The public pricing page lists the product families. The docs then clarify how billing works:
- Monthly commitment for plans in active status.
- Additional funds or usage logic once the commitment is exceeded.
- Different units and billing mechanics depending on the product.
The managed services page adds another commercial layer, with projects starting at $1,000 per month and one-time setup from $500 per standard scraper.
That makes one thing very clear:
Bright Data is not a toy purchase.
It is a business infrastructure decision.
If you want to evaluate that seriously, start with Bright Data here and map the pricing model to one real data-collection use case instead of browsing the pricing page in the abstract.
That evaluation should also include delivery expectations. Bright Data’s docs mention delivery and export options across APIs, webhooks, cloud storage, and file-based outputs, which matters because collection is only half the workflow.
ROI Calculation Frame :
The right way to think about Bright Data ROI is usually not:
- “How cheap is this compared with doing nothing?”
It is:
- How much internal engineering time does the team spend on brittle collection?
- How much analyst time is lost when data pipelines break?
- How much revenue or margin depends on having fresher market data?
If the business only needs occasional light research, Bright Data may be more than it needs.
If the business depends on continuous web data as part of pricing, monitoring, lead generation, ecommerce intelligence, or market research, the ROI conversation changes quickly.
Who Should Use Bright Data :
Bright Data makes the most sense for:
- Data-driven teams needing repeatable web data access.
- Companies monitoring markets, prices, listings, or public web signals at scale.
- Businesses that need a mix of proxies, APIs, datasets, or managed services.
- Teams that understand how the output connects to a real business workflow.
It makes less sense for:
- Casual one-off research.
- Teams with no clear plan for how to use the data.
- Buyers who only want the cheapest possible scraping utility and nothing more.

Verdict :
Bright Data is strong in 2026 because it is built like infrastructure, not like marketing fluff.
The official product pages show a real platform family. The billing docs explain that different products use different commercial logic. The managed services offering shows Bright Data is ready for teams that want outputs, not just tools.
That makes Bright Data most compelling when the business has a defined web-data use case and needs reliability, scale, and flexibility more than simplicity for its own sake.
If that sounds like your use case, start with Bright Data here and evaluate one real monitoring or collection workflow against the products Bright Data actually offers.
That kind of grounded evaluation is where the platform’s value becomes easiest to see.
If your team already depends on public web data for decision-making, start with Bright Data here and compare one live collection workflow against the cost of building and maintaining the same thing internally.
That is usually the fastest route to an honest yes-or-no decision.
FAQ :
What is Bright Data best used for in 2026?
Bright Data is best used for large-scale web data collection workflows involving proxies, scraping APIs, datasets, unlocking, or managed services.
Does Bright Data have simple flat pricing?
Not really. The official pricing and docs show that pricing depends on the specific product family and usage model you choose.
How much do Bright Data managed services cost?
The official managed services pricing page shows standard projects starting from $1,000 per month, with one-time setup from $500 per standard scraper and usage from $4 per 1,000 requests.
Who should not use Bright Data?
Businesses with only light or occasional data needs may find Bright Data to be more infrastructure than they actually need.